基础操作
文件.paragraphs
得到的是一个列表,包含了每个段落的实例,可以索引、切片、遍历
# from 从 docx这个文件中,导入一个叫Document的一个东西,Document是文档的意思
from docx import Document
# 文件 = Document() 可以理解为 Document就是一个类,这个操作也就是实例化的过程,生成对象为:文件
文件 = Document('c:/test.docx')
# 文件.paragraphs # 返回文档中每个段落集合,是一个列表,可以通过索引获取
print(文件.paragraphs)
print(文件.paragraphs[0])
print(文件.paragraphs[0:2])
段落.text
得到该段落的文字内容
from docx import Document
文件 = Document('c:/test.docx')
for 段落 in 文件.paragraphs:
print(段落.text)
块与文字
段落.runs 得到一个列表,包含了每个文字块,可索引、切片、遍历
文字.text 得到该文字块的文字内容
from docx import Document
文件 = Document('c:/练习.docx')
段落 = 文件.paragraphs[0]
块 = 段落.runs
for 文字 in 块:
print(文字.text)
文件的完整结构
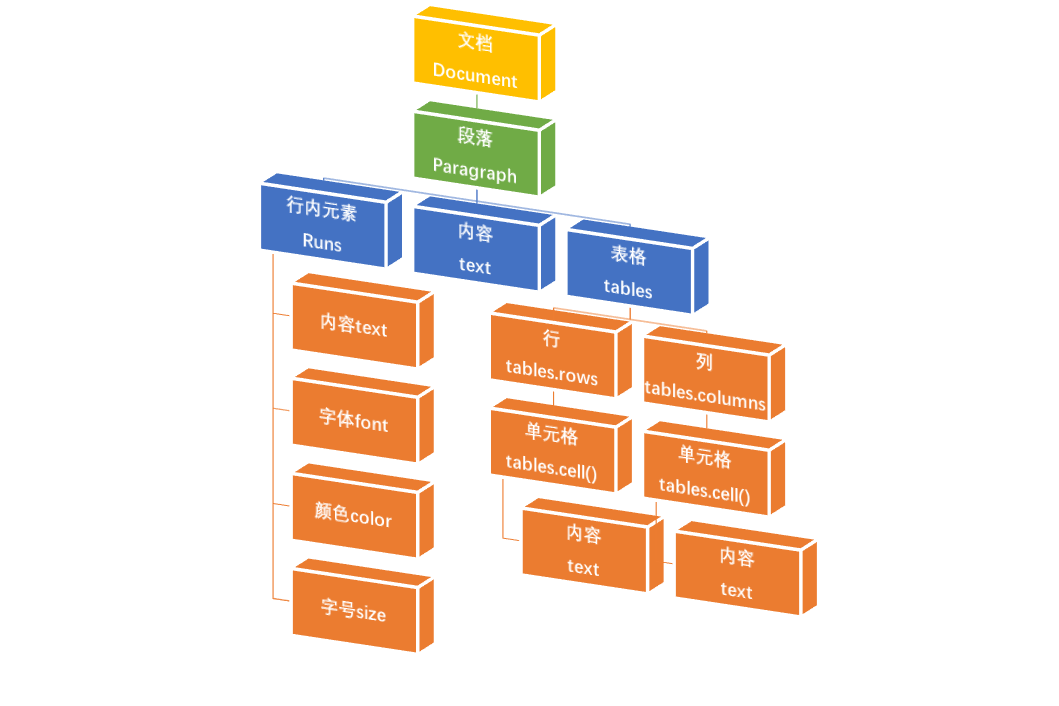
读取表格中的数字
from docx import Document
# 打开文档
文件 = Document('c:/练习2.docx')
i=0
j=0
# 遍历所有段落文本
for 段落 in 文件.paragraphs:
if '孙兴华' in 段落.text:
i+=1
# 遍历所有单元格文本
for 表 in 文件.tables:
for 行 in 表.rows:
for 单元格 in 行.cells:
if '孙兴华' in 单元格.text:
j+=1
print(f'孙兴华在文档中一共出现了{i+j}次')